Keras快速上手:基于Python的深度学习实战(谢梁)
- 无标签
时间
2018-09-16
")
 aa***k 2024年1月1日 12:44:37下载了******资料!
mi***1 2023年12月23日 10:30:51下载了******资料!
aa***k 2024年1月1日 12:44:37下载了******资料!
mi***1 2023年12月23日 10:30:51下载了******资料!

比较好的一本书。内容还不错,紧跟时代发展。非常适合新手入门。不过讲解的一般般。
对最近的学习工作很有帮助,希望能通过这本书的学习提高自己的能力
不适合想学keras的同学购买。原因如下:本书内容少,知识点浅,学习到的东西有限。其二,本书内容过于宽泛,很薄的一本书居然花了大篇幅讲安装过程。还泛泛的讲了图像处理,语言处理,爬虫数据,物联网这些大方向,而且是每一章一个大方面,基本学不到东西。其三,最为致命的是,因为作者是搞CNTK的,所以本书是keras+CNTK搭设的框架,我原计划是学习tensorflow + keras的,而本书在当当上说可以在CNTK/TENSORFLOW上随意切换。但是本书具体内容并没有讲怎么与TENSORFLOW切换,有欺骗消费者嫌疑。
书很好,希望有帮助吧,现在python挺火的,以后肯定会购买这方面更多的书。
这本书出得非常早,但 keras 讲得并不多,反而是为微软的产品做了好多广告。
《Keras快速上手:基于Python的深度学习实战》系统地讲解了深度学习的基本知识、建模过程和应用,并以深度学习在推荐系统、图像识别、自然语言处理、文字生成和时间序列中的具体应用为案例,详细介绍了从工具准备、数据获取和处理到针对问题进行建模的整个过程和实践经验,是一本非常好的深度学习入门书。
不同于许多讲解深度学习的书籍,《Keras快速上手:基于Python的深度学习实战》以实用为导向,选择了 Keras 作为编程框架,强调简单、快速地设计模型,而不去纠缠底层代码,使得内容相当易于理解,读者可以在 CNTK、 TensorFlow 和 Theano 的后台之间随意切换,非常灵活。并且本书能帮助读者从高度抽象的角度去审视业务问题,达到事半功倍的效果。
《Keras快速上手:基于Python的深度学习实战》从如何准备深度学习的环境开始,手把手地教读者如何采集数据,如何运用一些常用,也是目前被认为有效的一些深度学习算法来解决实际问题。覆盖的领域包括推荐系统、图像识别、自然语言情感分析、文字生成、时间序列、智能物联网等。不同于许多同类的书籍,《Keras快速上手:基于Python的深度学习实战》选择了Keras作为编程软件,强调简单、快速的模型设计,而不去纠缠底层代码,使得内容相当易于理解。读者可以在CNTK、TensorFlow和Theano的后台之间随意切换,非常灵活。即使你有朝一日需要用更低层的建模环境来解决更复杂的问题,相信也会保留从Keras中学来的高度抽象的角度审视你要解决的问题,让你事半功倍。
《Keras快速上手:基于Python的深度学习实战》以实际应用为导向,强调概念的认知和实用性,对理论的介绍深入浅出,对读者的数学水平要求较低,读者在学习完毕后能使用案例程序举一反三地应用到其具体场景中。《Keras快速上手:基于Python的深度学习实战》覆盖当前热门的传统数据挖掘场景和四个深度学习应用场景,根据我们市场调研,是目前罕有以应用为导向的介绍机器学习和深度学习的专业书籍,具备很高的参考价值和学术价值。
谢梁
现任微软云计算核心存储部门首席数据科学家,主持运用机器学习和人工智能方法优化大规模高可用性并行存储系统的运行效率和改进其运维方式。具有十余年机器学习应用经验,熟悉各种业务场景下机器学习和数据挖掘产品的需求分析、架构设计、算法开发和集成部署,涉及金融、能源和高科技等领域。曾经担任美国道琼斯工业平均指数独有保险业成分股的旅行家保险公司分析部门总监,负责运用现代统计学习方法优化精算定价业务和保险运营管理,推动精准个性化定价解决方案。在包括JournalofStatisticalSoftware等专业期刊上发表过多篇论文,担任JournalofStatisticalComputationandSimulation期刊以及DataMiningApplicationswithR一书的审稿人。本科毕业于西南财经大学经济学专业,博士毕业于纽约州立大学计量经济学专业。
鲁颖
现任谷歌硅谷总部数据科学家,为谷歌应用商城提供核心数据决策分析,利用机器学习和深度学习技术建立用户行为预测模型,为产品优化提供核心数据支持。曾在亚ma逊、微软和迪士尼美国总部担任机器学习研究科学家,有着多年使用机器学习和深度学习算法研发为业务提供解决方案的经验。热衷于帮助中国社区的人工智能方面的研究和落地,活跃于各个大型会议并发表主题演讲。本科毕业于复旦大学数学专业,博士毕业于明尼苏达大学统计专业。
劳虹岚
现任微软研究院研究工程师,是早期智能硬件项目上视觉和语音研发的核心团队成员,对企业用户和消费者需求体验与AI技术的结合有深刻的理解和丰富的经验。曾在Azure和Office365负责处理大流量高并发的后台云端研究和开发,精通一系列系统架构设计和性能优化方面的解决方案。拥有从前端到后端的丰富经验:包括客户需求判断、产品开发以及最终在云端架构设计和部署。本科毕业于浙江大学电子系,硕士毕业于美国南加州大学(USC)电子和计算机系。
1,深度学习的解决对象
适合解决数据量大,数据比较规范,但是决策函数高度非线性的问题
2,python文件中的__all__的作用
它是一个string元素组成的list变量,定义了当你使用 from
3,python中的单下滑线和双下划线的区别
"单下划线" 开始的成员变量叫做保护变量,意思是只有类对象和子类对象自己能访问到这些变量;"双下划线" 开始的是私有成员,意思是只有类对象自己能访问,连子类对象也不能访问到这个数据。
4,array.array()
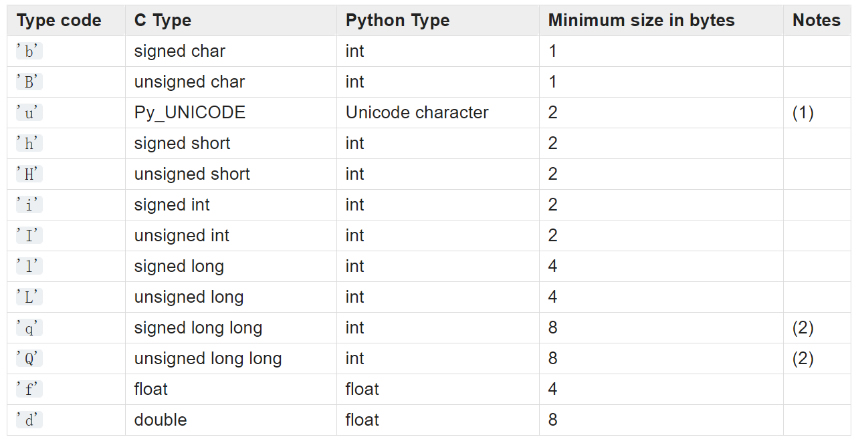
5,字符串按空格分隔成list
import re
regex = re.compile(r"(?u)\b\w\w+\b")
data_list = regex.findall(str)
6,从dict中获取值
dic = defaultdict()
dic.default_factory=dic.__len__
那么dic['a']就会等于0
1、链接失效请联系客服人员。
2、购买后如果链接失效可联系客服人员完善资源或进行退款办理。
3、资源均来源于网友分享及网络公开发表文件,所有资料仅供学习交流。
4、所收取费用仅用来维系网站运营,性质为用户友情赞助,并非售卖文件费用。
5、如侵犯您的权益,请联系客服人员,我们将会在第一时间进行处理。





